이 글을 읽고 나면
- AWS Lambda에 라이브러리를 사용하는 방법을 알 수 있습니다.
- AWS Lambda로 배치 작업을 어떻게 사용하는지 알 수 있습니다.
- PySQL과 pandas를 사용해서 SQL을 csv로 저장하는 방법을 알 수 있습니다.
배경
제가 진행하는 프로젝트에는 여러 가게들이 입점해 있습니다. 이 가게들의 매출 데이터를 정리해서 결제 금액을 정산해야 합니다. 이를 위해서 매주 월요일마다 지난 일주일 동안의 매출 데이터를 정리해서 csv 파일로 사장님에게 보내야 합니다. 매주 해야하는 작업이라 AWS Lambda를 사용해서 자동화하려고 합니다.
요구사항
- 매주 월요일마다 지난 일주일 동안의 매출 데이터를 정리해서 csv 파일로 저장합니다.
- csv 파일은 PM의 확인 가능하게 google drive에 저장합니다.
- 매출 데이터는 RDS에 저장되어 있습니다.
Lambda에 라이브러리 추가하기
AWS Lambda는 외장 라이브러리를 사용할 수 없습니다. 따라서 레이어를 사용해서 라이브러리를 추가해야 합니다. 레이어를 사용하면 라이브러리를 Lambda에 추가할 수 있습니다.
lambda 함수 생성
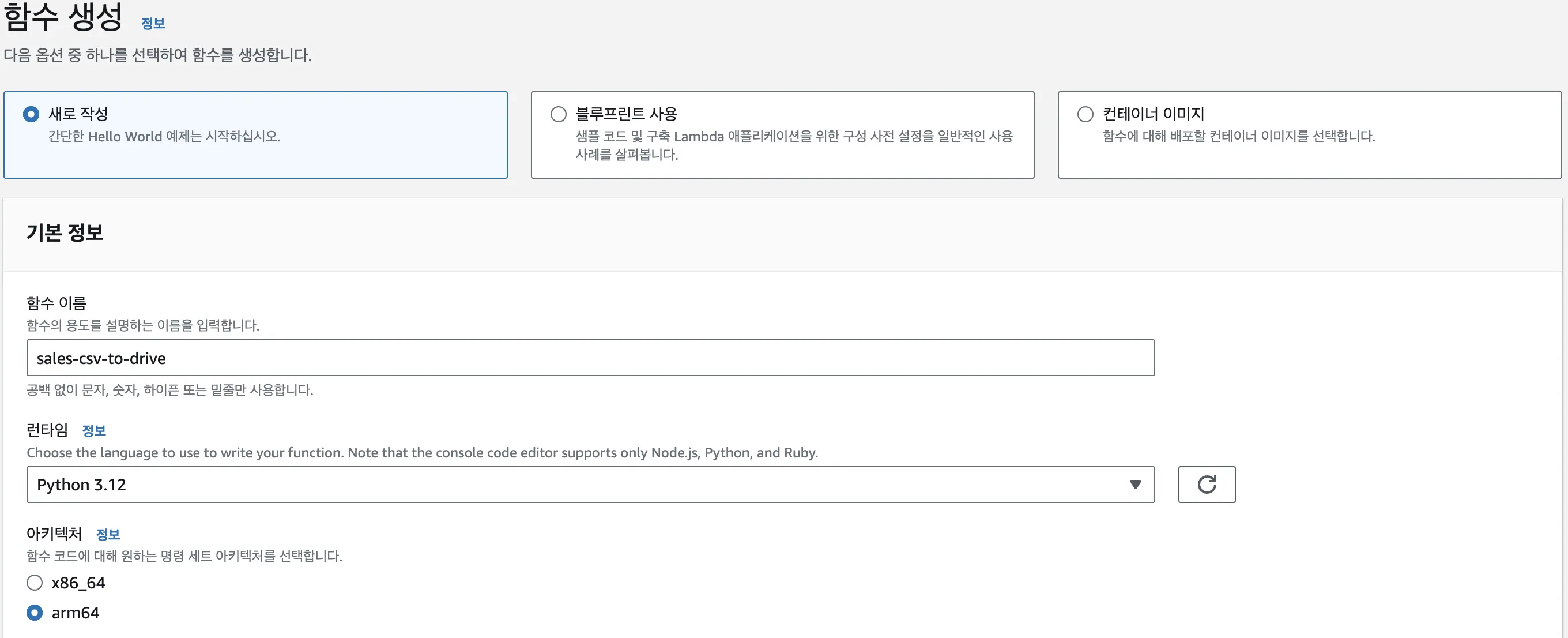
이름을 설정하고 함수를 생성합니다.계층 생성
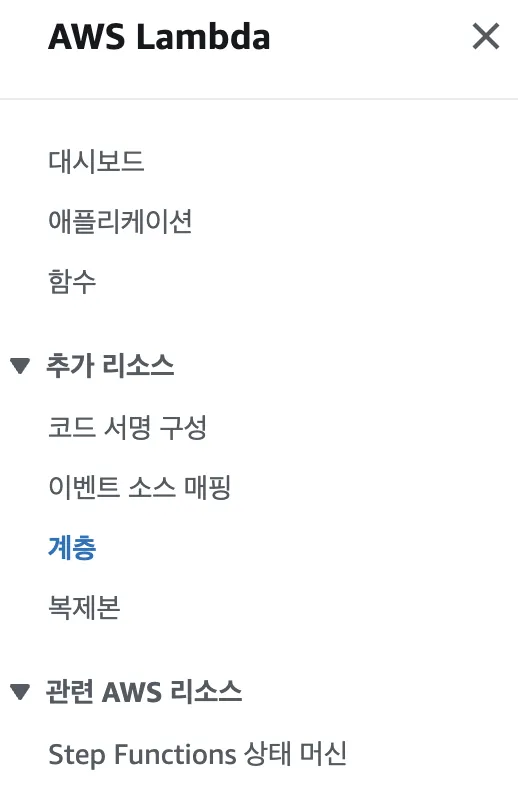
좌측 메뉴에서추가 리소스 > 계층을 선택합니다.로컬 폴더 생성
라이브러리를 다운로드할 로컬 폴더(python)를 생성합니다.라이브러리 다운로드
필요한 라이브러리를 다운로드합니다.
1
2
3
4
5pip3 install pymysql -t .
pip3 install google-api-python-client -t .
pip3 install oauth2client -t .
pip3 install httplib2 -t .
rm -r *.dist-info __pycache__S3에 업로드

파일 크기가 50MB를 초과하면 S3를 통해 업로드를 합니다.
계층 생성
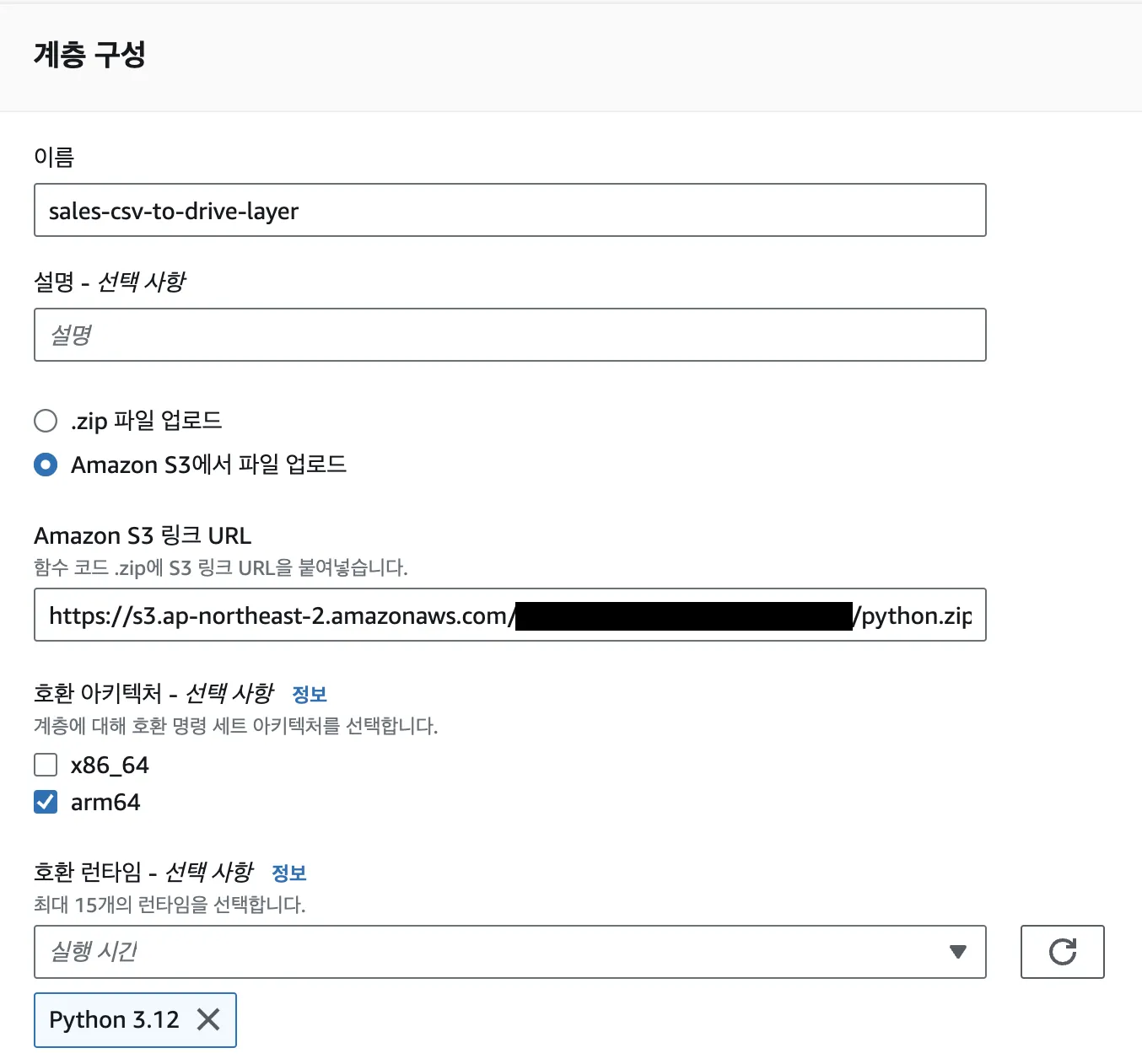
함수에 계층 추가

생성한 함수에 돌아와서Add a layer를 클릭합니다.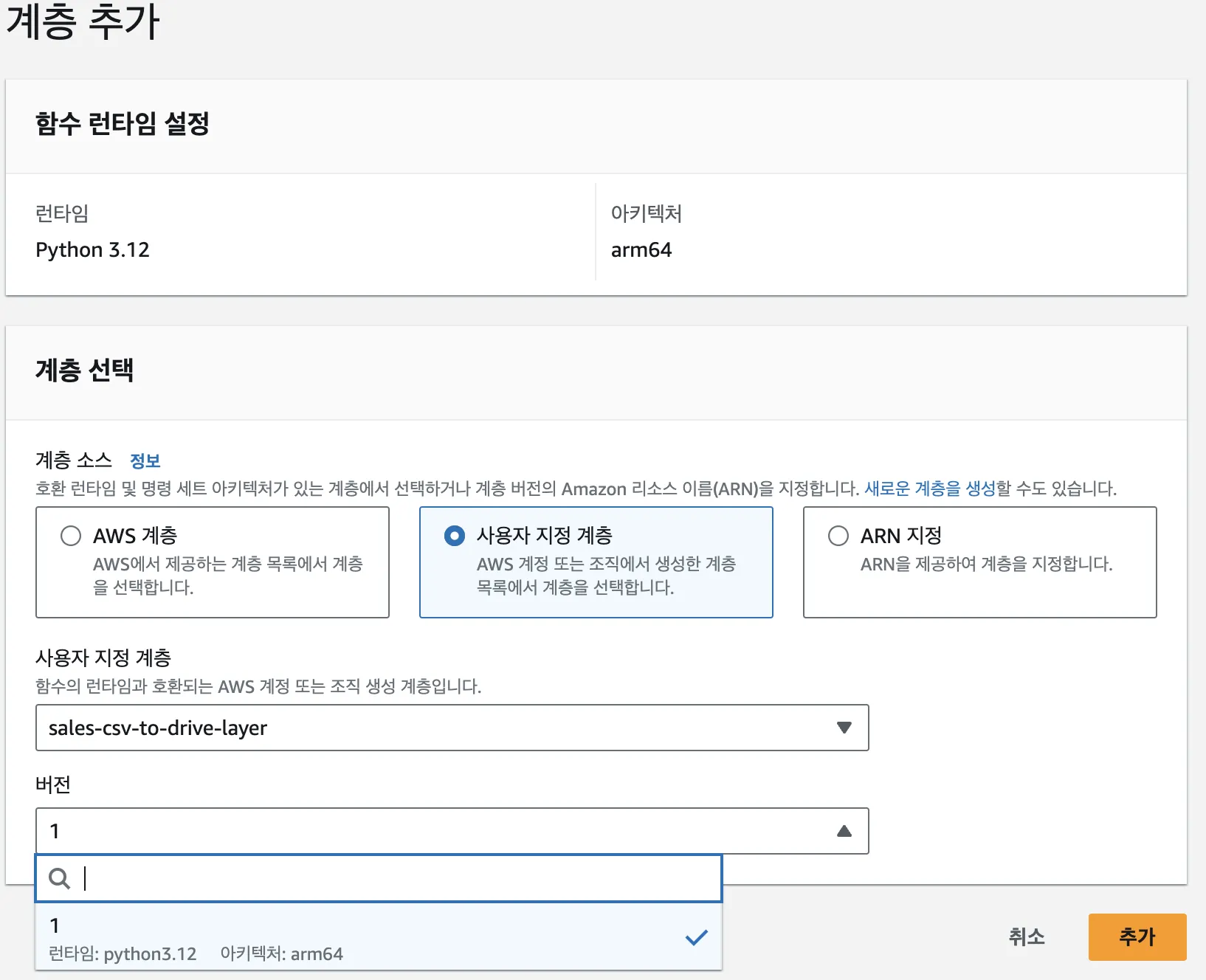
Lambda 함수 작성
함수 작성
1 | import json |
위의 코드를 보면 event[“dict”]같이 딕셔너리 타입으로 값을 받아서 사용하는 것을 볼 수 있습니다. 이는 Lambda 함수를 실행할 때 입력값으로 넣어주는 것입니다.
Configure event
- 아래처럼 이벤트를 생성해서 실행할 때 입력값으로 넣어줍니다.
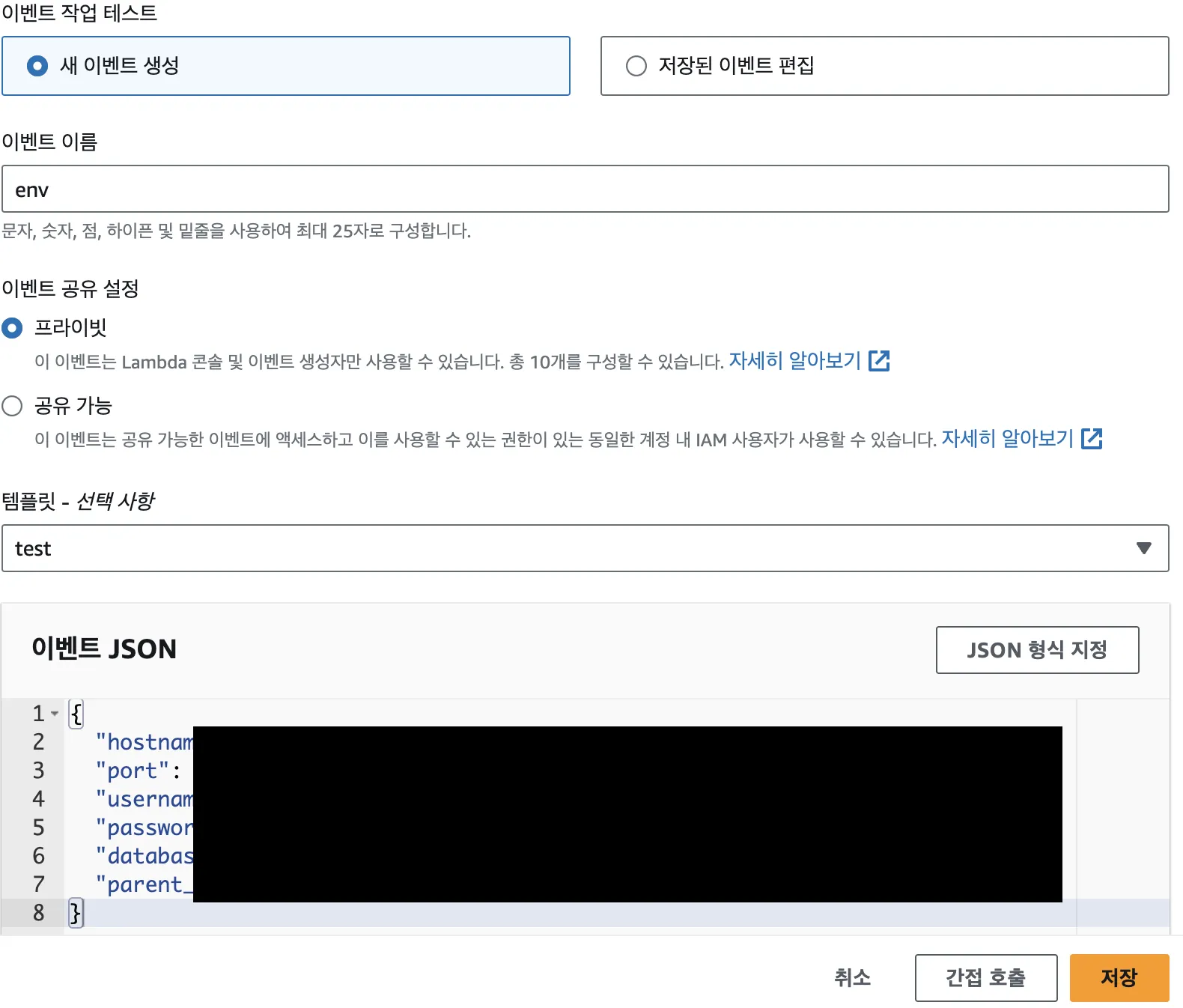
1
2
3
4
5
6
7
8{
"hostname": "RDS 호스트명",
"port": 3306,
"username": "유저명",
"password": "비밀번호",
"database": "데이터베이스명",
"parent_folder_id": "상위 폴더 ID"
}
테스트 실패
- 오류

테스트를 실행하면 시간 초과가 발생합니다. 구성 > 일반 구성 > 편집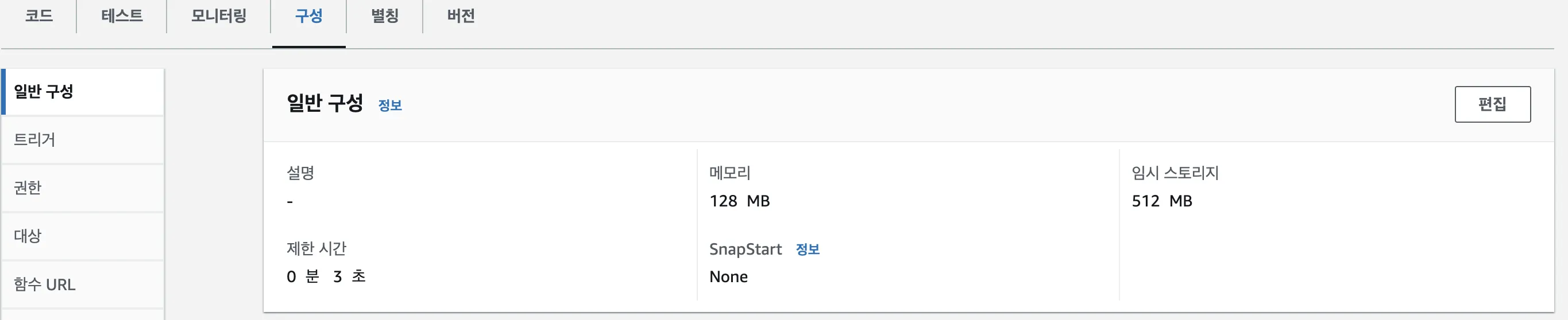
제한 시간을 늘려줍니다. (3초 -> 20초)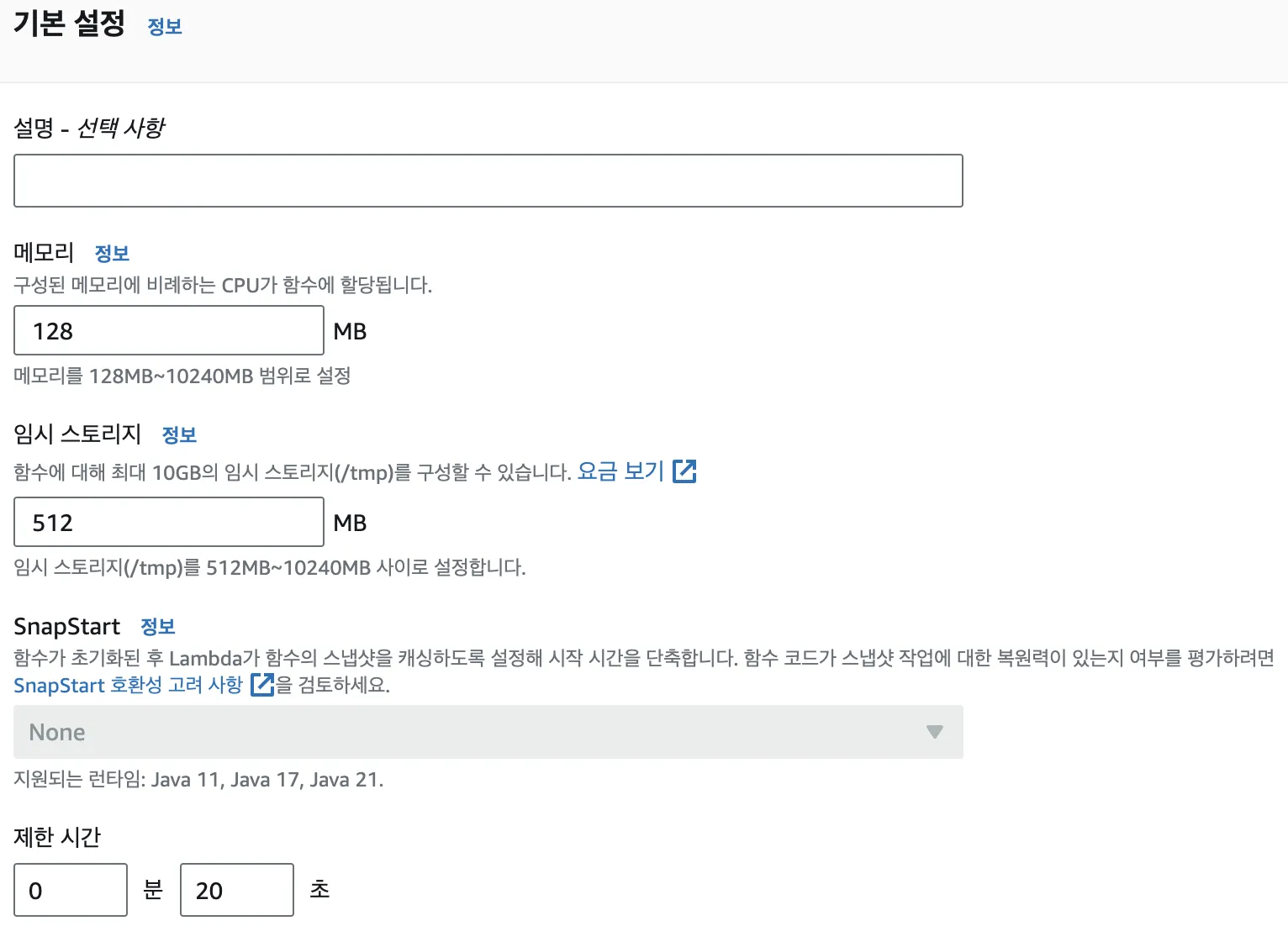
테스트 성공
deploy가 켜져 있으면 코드가 배포(저장)되지 않았습니다.deploy를 누르고 다시 테스트를 실행합니다.
- 실행 성공 (7.6초)
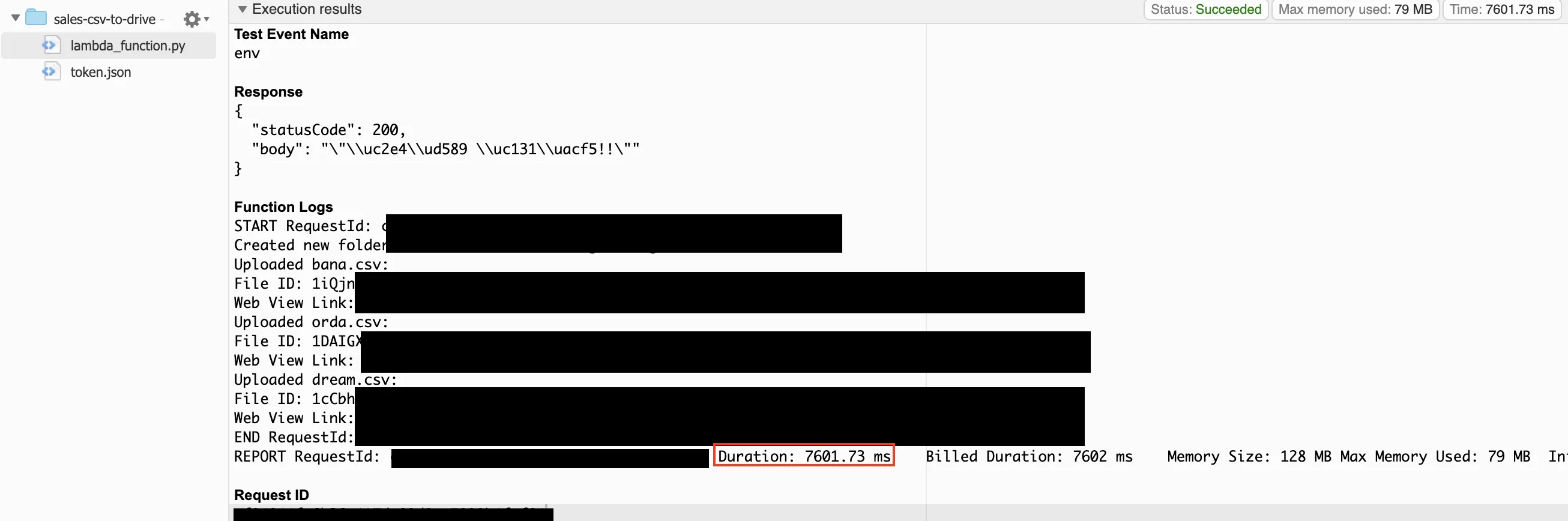
- 드라이브 확인
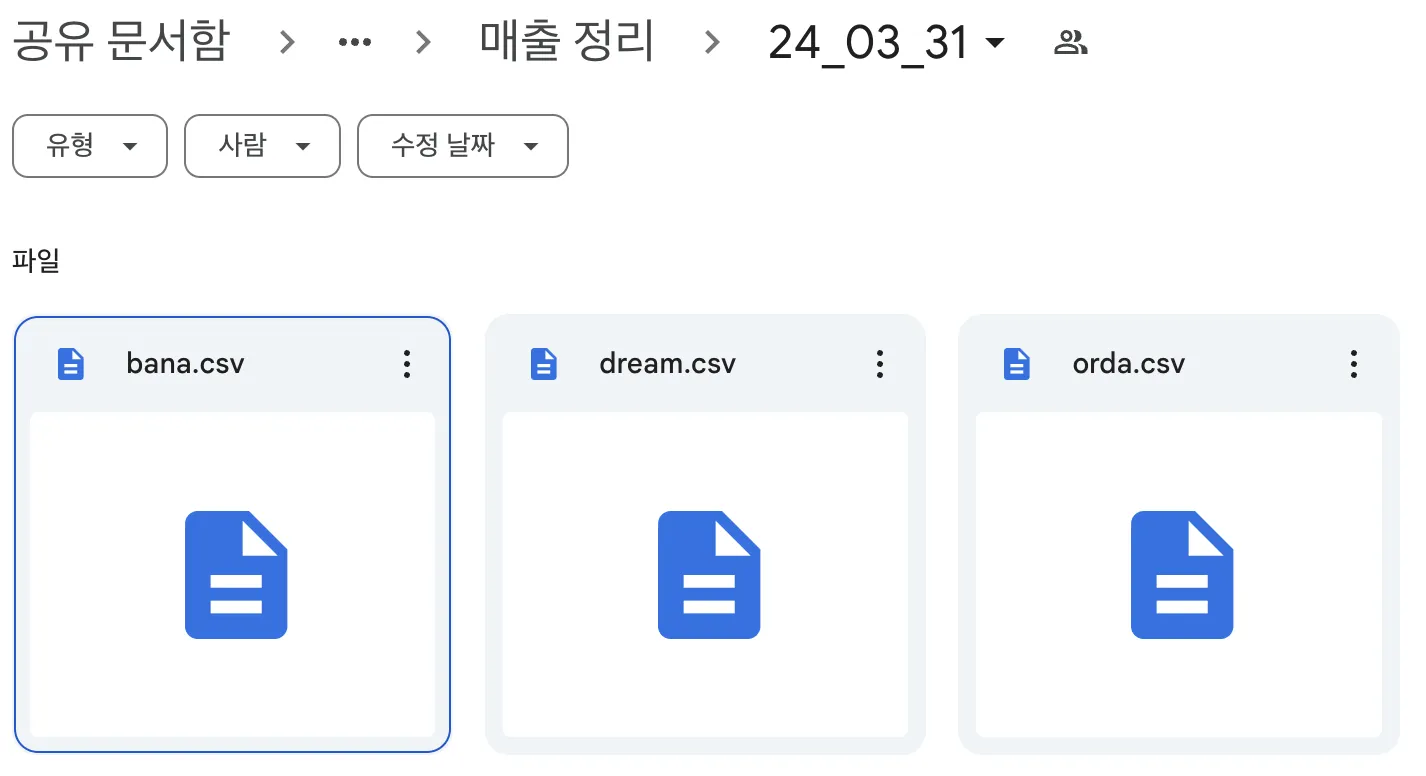
배치 작업 설정
함수 개요 > 트리거 추가를 클릭합니다.
EventBridge를 사용하면 주기적으로 실행할 수 있습니다.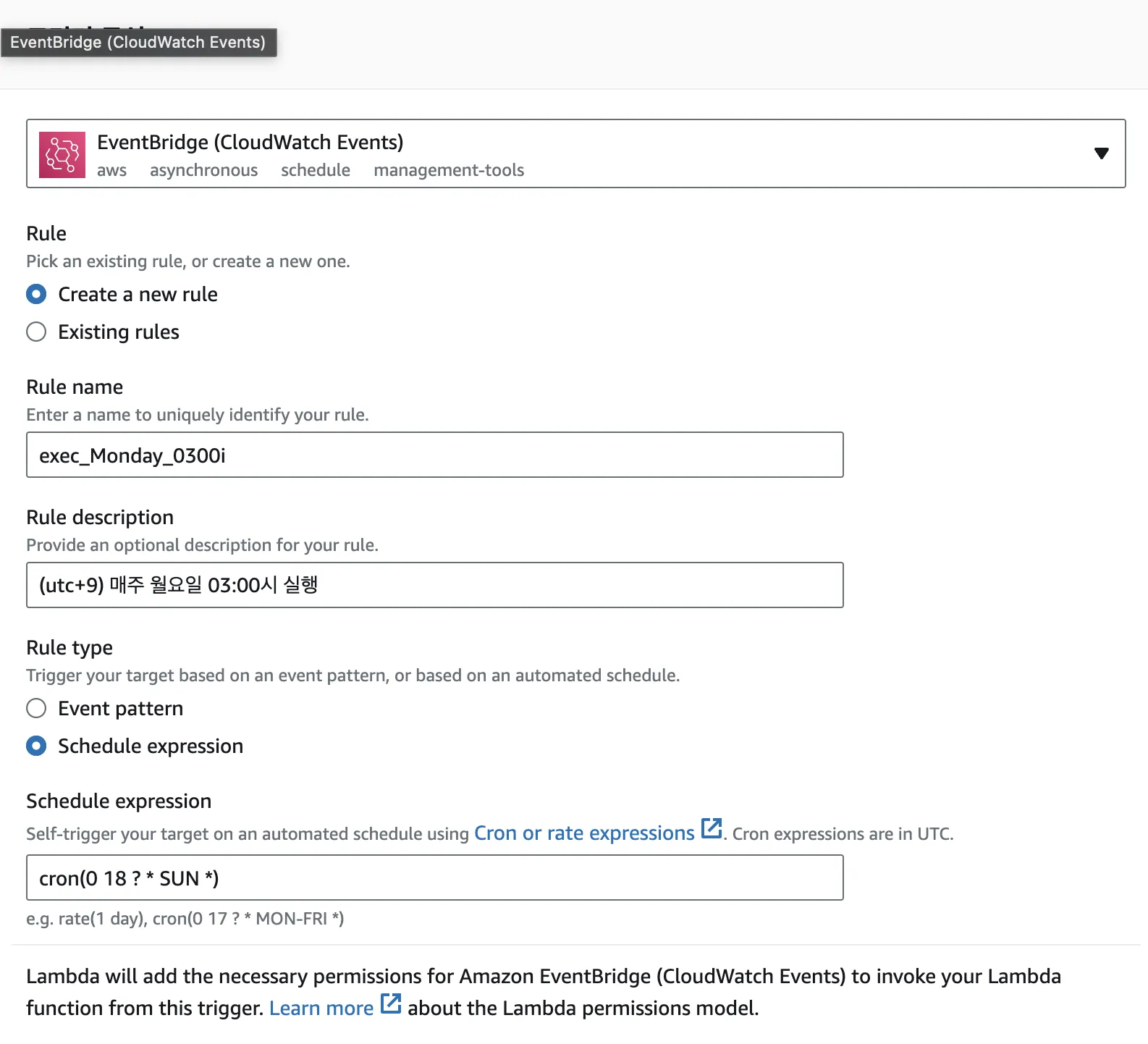
cron 표현식을 사용해서 주기를 설정합니다.UTC기준으로 설정하므로 주의합니다.- 이벤트를 설정 하기 위해서 이벤트 브릿지 상세에 들어갑니다.
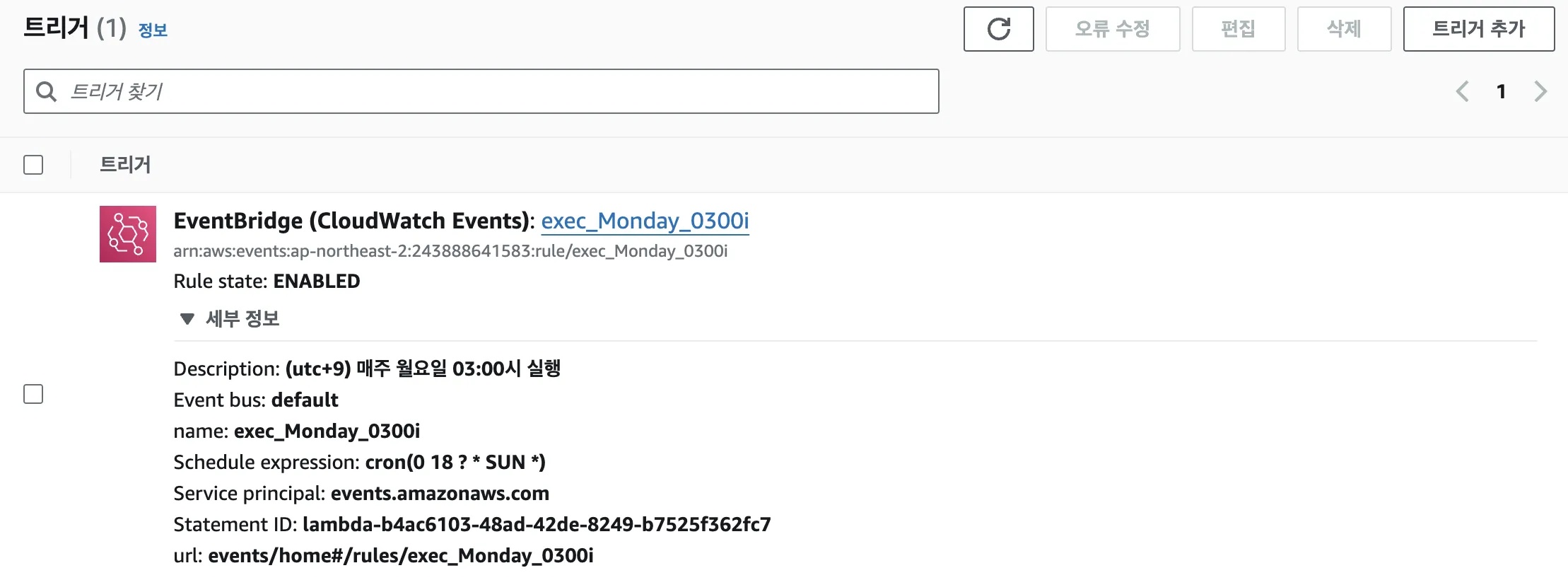
- 이벤트 브릿지
편집
대상 선택 > 추가 설정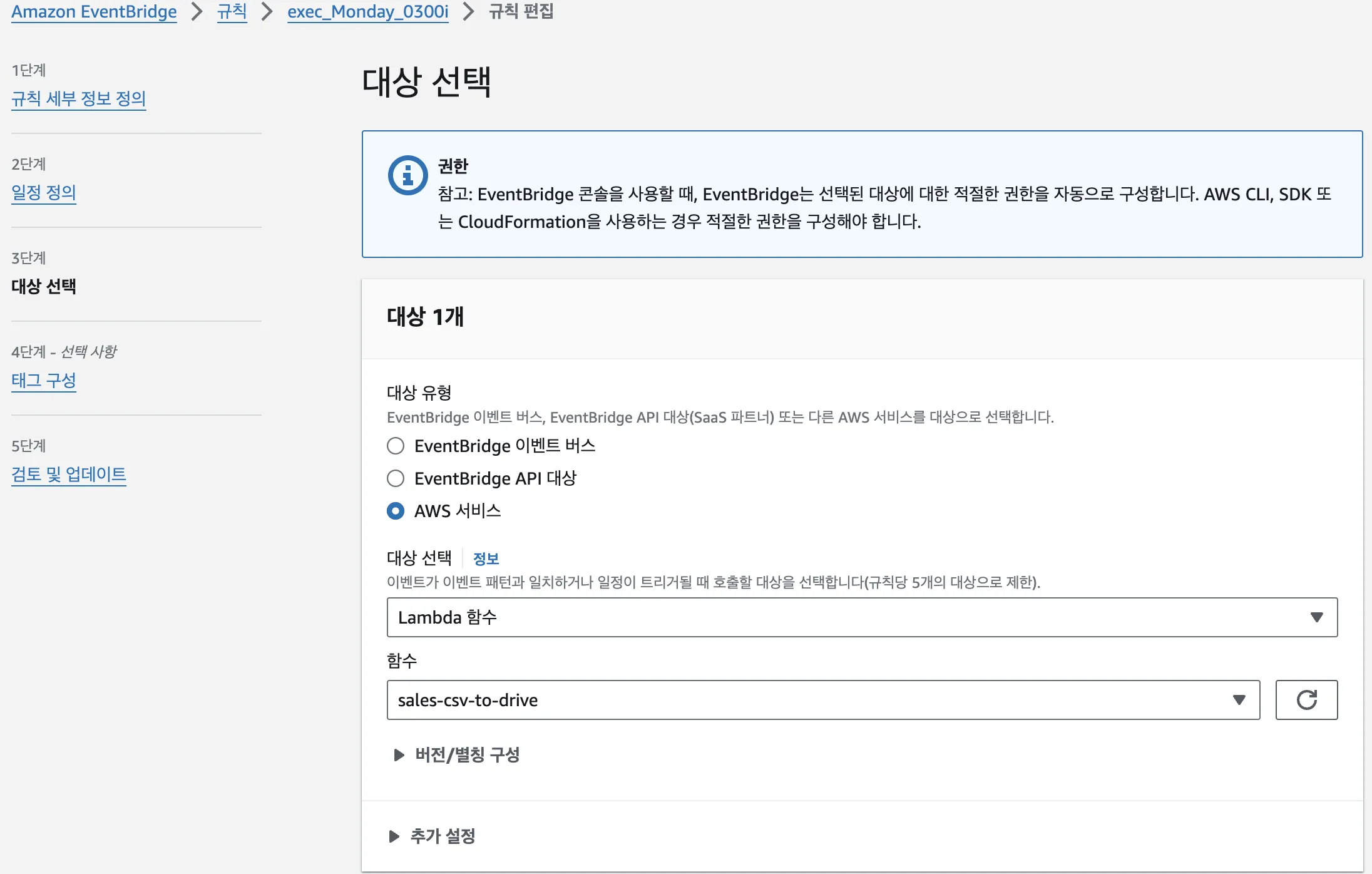
- 입력값을 설정하고
규칙 업데이트를 클릭합니다.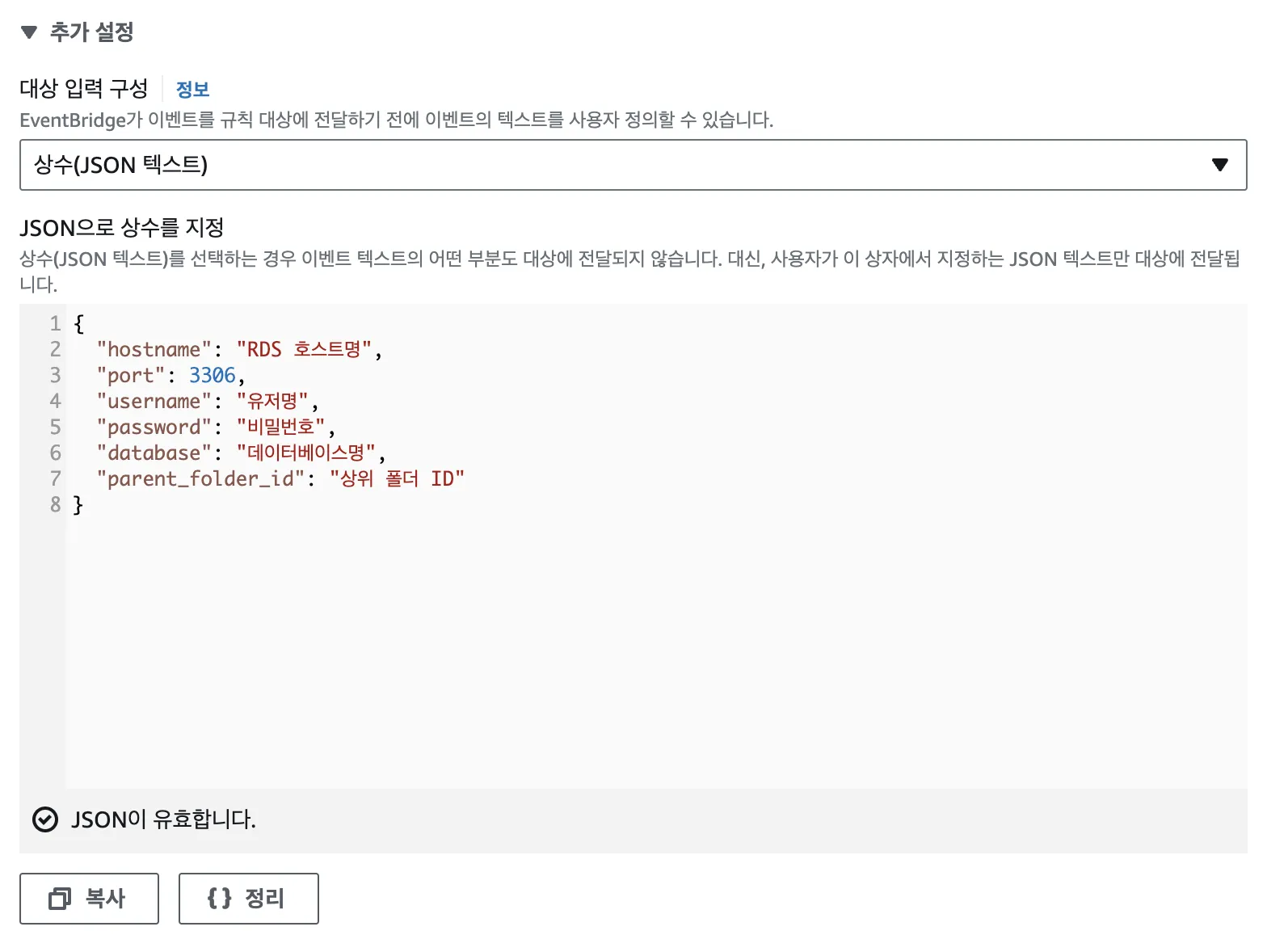
모니터링
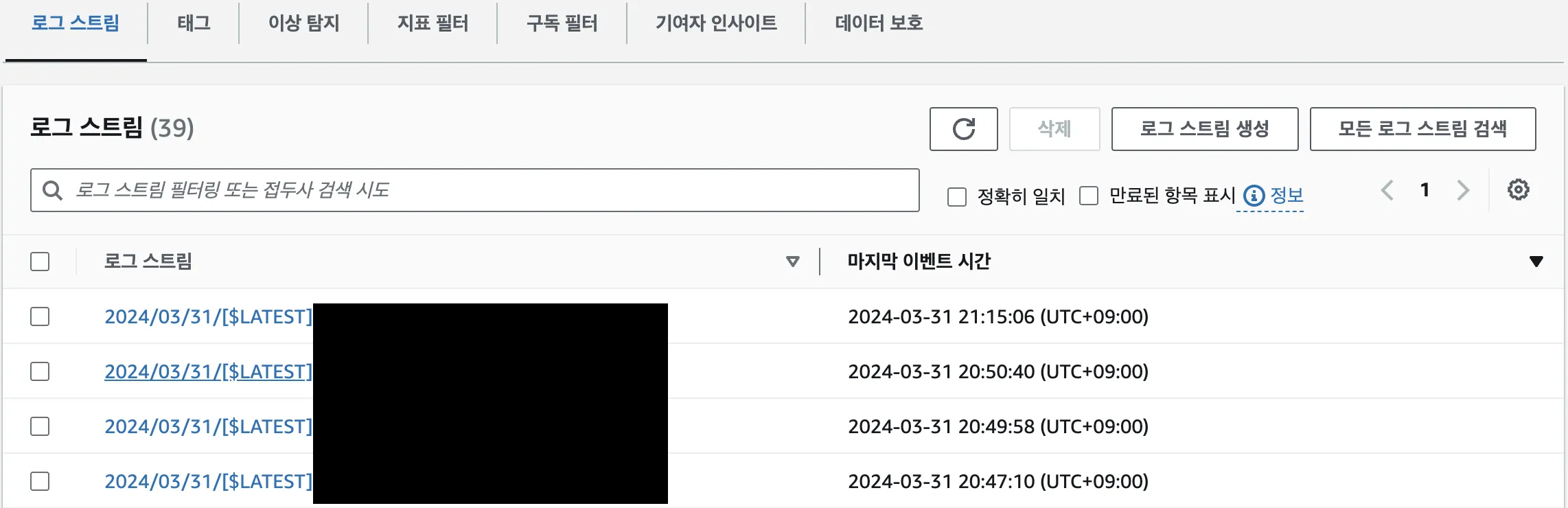
람다로 돌아와서모니터링 > 로그를 클릭하면 그래프로 확인할 수 있습니다.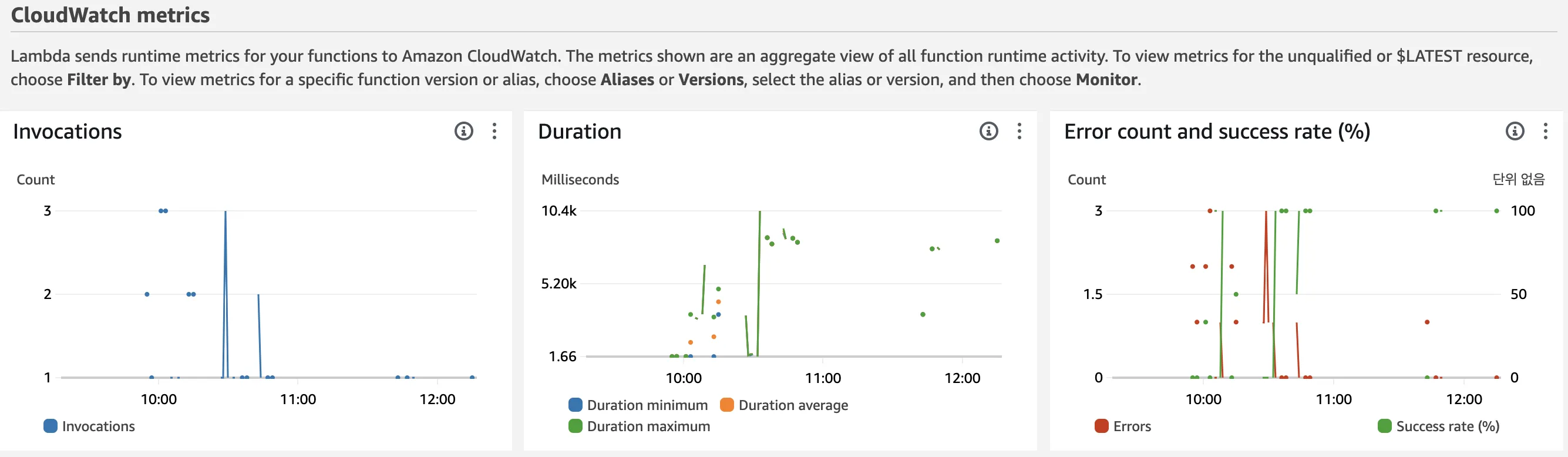
CloudWatch > 로그 스트림로 들어가서 상세 로그를 확인할 수 있습니다.